


Using AI for 3D rendering—a practical guide for designers
[ad_1]
The slow, meticulous process of creating high-quality renders is often incompatible with the fast pace required from early concept ideation. How do we find that balance?

As a product designer with a strong passion for 3D, I’ve always tried to find every opportunity to bring my hobby into my work, helping to elevate the quality of the work. Unfortunately, the slow, meticulous process that is involved in creating high-quality renders often isn’t compatible with the fast pace required early stages of conception and design.
In digital product design, concepting is a critical phase where ideas begin to take shape. It’s more than just sketching initial designs; it involves imagining the product’s functionality, user experience, and aesthetic appeal. Assets created during this stage are crucial. They not only help illustrate ideas but also are key in embedding the concept into something more tangible. This helps evoke the emotions you ultimately want your product experience to evoke for the end user—and is useful for testing and approval from clients.
In my experience, designers usually gleam the internet trying to find assets that fit-ish what they have in mind, before creating the appropriate images in the later stages of design. This is frustrating. It’s just an approximation, usually an amalgamation of ill-fitted illustration that also takes a considerable amount of time away from design.
Over the past year, I’ve explored integrating AI-powered rendering into my workflow. Not only does it accelerate the process of creating and iterating on these images, but it also makes it much more accessible to designers without as deep of expertise in 3D (and most of it is open source!). This new workflow is what I’d like to share with you today.
The beauty and the challenge of traditional 3D rendering

Traditional 3D workflows stand as the cornerstone of high-fidelity visual creation. The process of creating these images is broadly divided into three phases, each requiring meticulous attention to detail and a deep understanding of both the tools and the artistic process, and requires years and years of experience to master.
- Modeling: In this stage, 3D models are crafted for the scene. For less experienced artists, this process can be pretty destructive, requiring starting over if mistakes are made. Complete knowledge of tools specific to your 3D software of choice is necessary for this step.
- Texturing and Lighting: This phase involves adding color, texture, and lighting to models, essential for realism and mood-setting in the scene. Depending on the direction we are going for the scene, this step can be fairly simple to extremely complicated.
- Rendering: Finally, renderers like Octane and Blender’s Cycles are used for their realistic light physics, enabling a high level of detail and flexibility in creating everything from realistic to abstract visuals. For complex scenes with animation, this step can take hours for just a few seconds of footage.

Unbiased renderers like Octane and Blender’s Cycles, as their name implies, simulate lighting and materials with less bias, meaning they don’t take shortcuts in the simulation process. They essentially cover the scene with virtual photons, bouncing around as they gather information about the scene and end in the virtual camera’s eye.
This results in images of exceptional quality and realism but requires considerable computing power and time, making them a resource-intensive option. This also means powerful GPUs are necessary, which isn’t always affordable to people just curious about exploring creating these images. These tools excel in replicating the real-world physics of light, offering an unmatched level of detail and realism. They provide the flexibility to create anything from photorealistic scenes to surreal, abstract visuals, making them invaluable in the arsenal of a 3D artist.

Not everyone knows how to use these complex render tools. In fact, very few people do. I’ve been learning and practicing 3D for more than 3 years, on the side, and haven’t even started to scratch the surface of what is possible with Blender.
Crafting an elegant image involves not only a lot of control and technical prowess over the powerful tools available to you but also a deep understanding of art and design principles. This can feel overwhelming and discouraging. Adding this the complexity, this detailed and controlled approach is not suitable for fast-paced concepting and iteration, particularly in the early stages of a project.
It can be really challenging to spend 4 hours creating and rendering a single image when you’re trying to come up with a wide range of directions and ideas in only a few days.
The potential and limitations of AI-generated imagery

AI-generated images, on the other hand, introduce a realm of near-infinite visual possibilities, facilitating rapid iteration where a minor prompt adjustment can lead to an entirely new creative direction. The ease of iterating with AI-generated images is unmatched — even a slight tweak in a prompt can lead to a significant shift in visual style.
There’s one major problem with this approach, though: lack of control. If we tried to create an image similar to the one in the introduction, with a specific interior style, composition, and setting, we might as well try to play the lottery.

Generating images over and over until you stumble on one that strikes the right balance of style, composition, lighting, and layout you have in mind simply isn’t sustainable. This process can be painstakingly slow and frustrating, particularly when trying to match the image to the aesthetic requirements of specific products and brand.
Control is the crux here. The real challenge lies in leveraging the speed and detail of AI while maintaining a decisive grip on the creative output.
AI-enhanced 3D: creativity and control

A simple scene created with minimal effort can immediately turn into a complex render with the help of AI rendering. Here, I explored recreating Benjamin’s living room in 3D from scratch and in a different style.
The integration of open-source AI tools into tools like Blender such as ControlNet mark a first step at solving some of these challenges laid out above. ControlNet can read information in the scene, such as:
- Depth: how far is any given object from the camera and each other.
- Lines: where are the edges of objects in the scene?
- Semantics: Recognize what objects are in the scene (e.g this is a couch; this is a lamp).
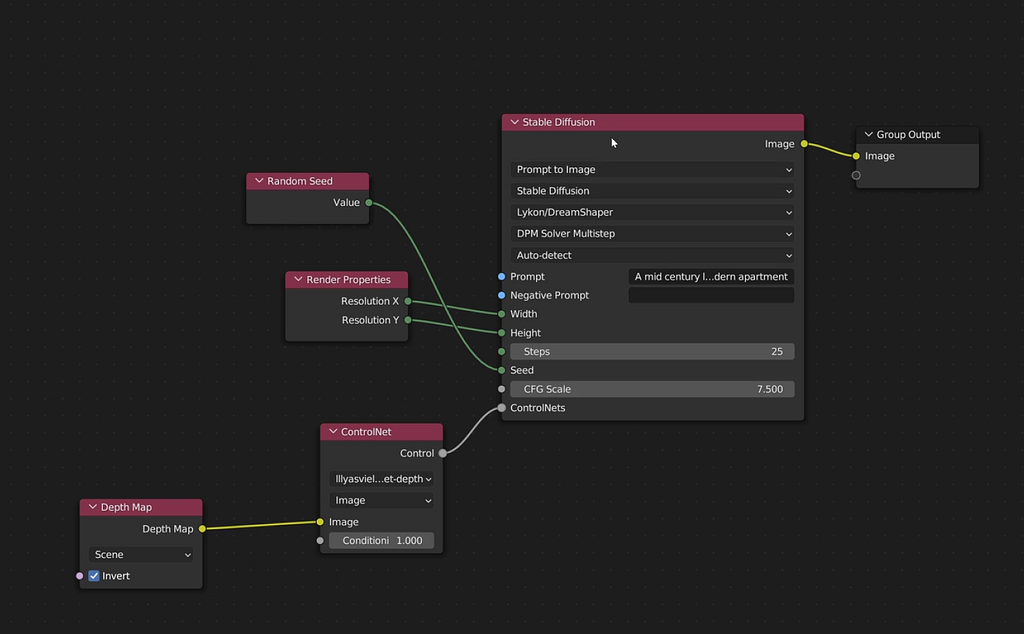

This new workflow allows designers to retain control over their work while benefiting from the flexibility AI offers. Designers can start with a simple 3D model and, using AI, rapidly explore different visual directions and make quick adjustments. This approach results in a collaborative process where the precision of traditional 3D modeling meets the adaptability and speed of AI:
- Modeling: Create simple 3D models (although advancement in generative 3D can simplify this step already), with a focus more on proportions, layout, and composition over minute details.
- Generate: ControlNet shares information about the scene with the diffusion model, which in turn generates an image keeping composition and subject intact. (If you’ve seen the custom QR codes, they use ControlNet to achieve this)
- Iterate: Tweak the control over the generated image. If control is heavy, AI will make sure the renders matches the proportions of the model closely, but restricting detail and “creativity”.

A key advantage of starting with a basic 3D scene is the freedom to explore it as if maneuvering a camera, easily adjusting perspective, composition, and focal lens. Here, we get closer to the lamp in the middle of the scene.

You can see the before and after, with the DepthMap first and the generated image second. Note the marbling on the lamp, the reflection on the table and the details on the table.

Examples of the variance in style but consistent composition / proportions that can be achieved by changing the prompts but using the same 3D inputs.

Interestingly, when two of the same objects are put side by side, the model understands it and generates them consistently.
One of the key benefits of this AI-enhanced workflow is the ability to share early concepts more efficiently with both creative teams and product designers. Presenting AI-enhanced visuals early in the process helps set a concrete direction for the project, facilitating better communication and saving valuable time and resources.

This methodology also supports the creation of consistent mood boards, which serve as vital reference points throughout the design process. These mood boards can be quickly adjusted and refined, allowing us designers to create a cohesive visual language that guides the project’s art direction.
Additional tools are coming out on a regular basis, which are also making this workflow more powerful. Krea, powered by LCM-LoRA’s (Latent Consistency Model — Latent Residual Adapters), a new innovation in the world of diffusion models, provides near real-time rendering, reacting almost instantly to your input.


Guiding the chaos: custom trained models

So far in this article, the use of AI in design has primarily revolved around its speed and capacity for collaborative creation. However, a common challenge due to the fact most models are designed to be generalist is the intricate prompt engineering required to nail a specific style.
If our goal is to use these images for a product we have a specific vision for, we can quickly find ourselves back to playing the generative loto, generating images and tweaking prompts over and over until we find something suitable for our project.

Thankfully, diffusion models can be trained to become experts in a specific style or art direction. By compiling sources of inspiration, we can train our models using tools like Dreambooth to have more consistent outputs while keeping the creative control we worked hard to maintain.

Quick explorations based on simple letters. These set of images feel consistent, and the only prompt input was to clarify the material I wanted it to generate. The rest of the images was dictated by the custom model. It was interesting to notice how the generated images seem to follow the physical constraints of the materials.
AI is most beneficial in the early stages of design, such as internal concept development and brainstorming. If trained properly, the model and AI-generated visuals serve as a basis for creative discussions within the team, offering a wide range of possibilities for inspiration and preliminary ideation.

Maybe I’m being a little too optimistic, but in my mind, the goal of employing AI in the design workflow is not to replace the need for artists but to enhance and expedite the conceptual phase before budgets are allocated for artist contributions. This approach is similar to what every designer currently does: gather images online that match a general style for initial concept stages, later transitioning to licensed assets or custom-created artwork.
This is about using AI as a tool that complements human creativity and helps explore initial ideas and directions quickly, while recognizing the value of professional artistry in bringing the final design vision to fruition.

The use of AI in 3D design workflows for generating quick illustrations and images is really only the tip of the iceberg. Innovations are happening at breakneck speeds. I have no doubt in my mind that AI is the future of rendering, and AI Renders will ship natively with 3D software as well as game engines. In fact, AI is already being used for de-noising and upscaling renders in Blender, as well as optimizing rendering times in the latest Pixar’s Elements, optimizing frame rates in Unreal Engine.
Control over style and composition are still the major hurdle for these workflows to be more widely adopted. On top of that learning how to use tools like Stable Diffusion is still a pretty confusing and technical affair. The technology behind diffusion models being shrouded in mystery for anyone without a degree in neural networks and computer science certainly doesn’t help. Additionally, the interfaces users have to interact with are dreadful, mostly because of how fast developers are building them, and there is a lot of improvement to find there.
Tools such as Spline are at the forefront of making both 3D and AI rendering more accessible to a wider range of designers. Recently, they launched their own take on AI renders “Style Transfers” which uses similar techniques to what we’ve discussed today. By simplifying these complicated processes, they are democratizing the ability to create high-quality visuals, opening up new possibilities for designers regardless of their technical expertise.
Looking ahead, the next big frontier in this evolving landscape is video generation and generative 3D. Startups like Runway, as well open source tools such as Stability’s video diffusion model are making quick improvements in allowing users to animate the images they generate.

So far, motion from a still frame is limited, but video2video outputs will become better and better, allowing us to see the full potential of leveraging AI rendering for product animations.
If you’re interested, I’d love to write a more technical follow-up article on how to combine some of these innovations and bring more motion into your creations. Just let me know in the comments.

Links & Resources
Guides:
Installing Stable Diffusion for Automatic111
https://stable-diffusion-art.com/install-windows/
Guide to training custom models in Automatic111
https://www.nextdiffusion.ai/tutorials/dreambooth-super-easy-ai-model-training-with-automatic-1111
Guide to use LCM’s in Automatic111
https://github.com/0xbitches/sd-webui-lcm
Tools mentioned:
Stable Diffusion for Blender Ad-On
https://blendermarket.com/products/ai-render
Dream Textures
https://github.com/carson-katri/dream-textures
Spline Style Transfers
https://spline.design/ai-style-transfer
Runway
https://runwayml.com/
Blender
https://www.blender.org/
Articles:
- Realtime generative AI art is here thanks to LCM-LoRA
- What is LCM-LoRA? A Stable-Diffusion Acceleration Module
- Unbiased rendering – Wikipedia
Using AI for 3D rendering—a practical guide for designers was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.
[ad_2]
Source link

")